
此篇简要介绍下来自Twitter的分布式ID生成算法——SnowFlake。
一些传统ID生成方式的弊端
1. 内置随机ID函数
一些语言内置的随机ID生成函数,存在着生成的ID位数过长,ID无序导致入库性能较差等问题。
另外,如果是UUID的生成方式,则需基于机器MAC地址,有安全风险,且不是分布式的。
2. 数据库自增主键
严重依赖数据库,性能不高,可用性也有风险。
3. Redis的INCR方案
QPS测算在20W+左右,如果超过这个范围则不合适。
SnowFlake算法
SnowFlake是Twitter公司所采用的一种算法,目的是在分布式系统中生成全局唯一且趋势递增的ID。
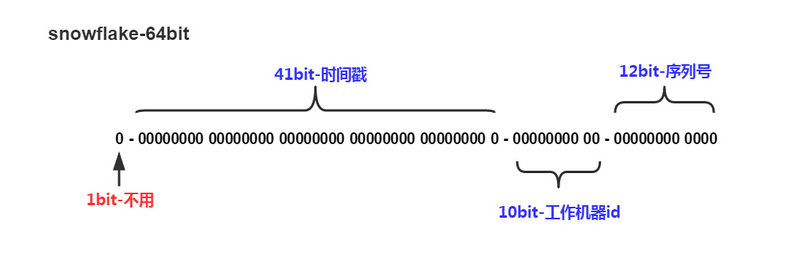
- 第1位代表符号位,始终为0;
- 第2组代表时间戳,精确到毫秒;
- 第3组代表工作机器id,高5位是datacenterId,低5位是workerId;
- 第4组代表序列号,这个值在同一毫秒同一节点上从0开始不断累加;
理论上SnowFlake方案可达到的QPS约为409.6w/s。
SnowFlake的优缺点
优点
- 内存生成,不依赖外部DB,确保高性能高可用。
- 生成的ID呈趋势递增,在插入索引树时表现性能较好。
缺点
- 依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序。
- 为了解决时钟问题,有些公司采用ZK去比较当前workerId也就是节点ID使用的时间是否有回拨,如果有回拨就进行休眠固定时间,看是否能赶上时间。如果能赶上的话,就继续生成ID。如果一直没有赶上达到某个值的话,就报错处理。
业务对ID号的需求
- 全局唯一性
这是ID生成的天然需求。 - 趋势/单调递增
为了保证系统(如DB)写入的性能。 - 信息安全
防止关键业务信息(如订单量)被竞对根据ID数量计算出来。
如果感兴趣,也可以看下美团点评的分布式ID生成系统(Leaf)的实现,其中使用了一些缓存策略,提高了性能和稳定性。