
此篇简单聊一下消息队列方面的内容。
消息队列(message queue)是一个经常用到的中间件技术。
消息队列的作用
- 解耦应用
- 异步化消息
- 流量削峰填谷
- 最终一致性(最终一致性不是消息队列的必备特性,但确实可以依靠消息队列来做最终一致性的事情。)
- 广播
常见的消息队列组件
常见的消息队列组件主要有:
1. Kafka(Scala开发)
2. RocketMQ(Java开发,设计时参考了 Kafka,并做出了自己的一些改进)
3. RabbitMQ(erlang开发)
4. ActiveMQ(Java开发)
5. ZeroMQ(C开发)
优劣势综合对比
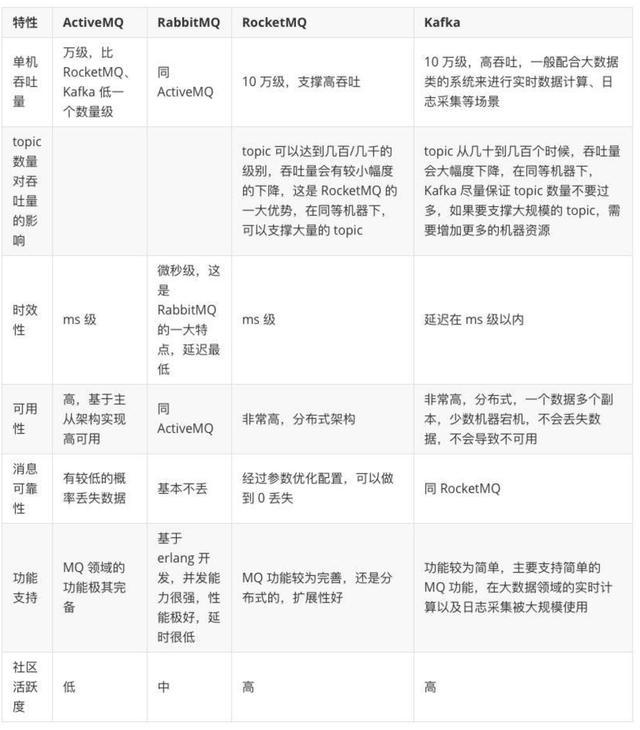
虽然消息队列组件众多,但最常见的还是Kafka和RocketMQ两种。它们的一些对比如下:
| 特性 | Kafka | RocketMQ | RabbitMQ |
|---|---|---|---|
| 开发语言 | Scala | Java | Erlang |
| 单机吞吐量 | 10万级,单机写入TPS约在百万条/秒,吞吐量三者最高 | 10万级 | 不到10万 |
| 时效性 | ms级以内 | ms级 | |
| 可用性 | 非常高(分布式架构) | 非常高(分布式架构) | |
| 功能特性 | 主要应用于日志采集/大数据实时计算领域,支持主要的MQ功能,不支持消息查询,支持按Offset进行消息回溯 | 功能完备,扩展性佳,经过参数优化配置消息可以做到0丢失,支持根据Message Id查询消息也支持根据消息内容查询消息,持按照时间来回溯消息精度达毫秒 | 基于AMQP协议实现,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次 |
| 缺点 | 单机队列load过多会导致发送消息响应时间变长,短轮询的方式决定了实时性取决于轮询间隔时间,消费失败不支持重试,支持消息顺序但是一台代理宕机后就会产生消息乱序 | 可能需要自己定制不同语言的client | |
| 其它特点 | 基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输,适合产生大量数据的互联网服务的数据收集业务 | 天生为金融互联网领域而生,对于可靠性要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况。目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binlog分发等场景。 | |
 |
关于消息丢失的问题
- Kafka如何配置不当会丢消息
- 消息落盘时机:消息落盘有异步刷新和同步刷新两种,明显异步刷新的可靠性要高很多。但在某些场景下追求性能而忽略可靠性,可以启用。
- 消息存储维护:在机器或存储环境发生变化时,可能丢失数据。
- RocketMQ如何保证不丢消息
- 采用同步阻塞的发送方式,同步等待发送结果,利用同步发送+重试机制+多个master节点,尽可能减小消息丢失的可能性。
- consumer端要保证消费消息的可靠性,主要通过At least Once+消费重试机制保证。
RabbitMQ
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP,SMTP,STOMP。它比较重量级,更适合企业级的开发。
Redis
- 使用Redis做队列有局限性,当数据大小超过了10K,Redis就慢的无法忍受。
- Redis做队列没有ack机制保障。
- Redis 的 list(列表) 数据结构常用来作为异步消息队列使用,使用 rpush/lpush 操作入队列,使用 lpop / rpop 来出队列。
- 如果redis的队列空了,客户端会陷入 pop 的死循环。不停地 pop 但没有数据,这就是浪费生命的空轮询。空轮询不但拉高了客户端的 CPU,redis 的 QPS 也会被拉高。解决这个问题的办法是使用 blpop/brpop。这两个指令的前缀字符b代表的是blocking,也就是“阻塞读”。阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消息的延迟几乎为零。用blpop/brpop替代前面的lpop/rpop。